ATTENTION, LEARN TO SOLVE ROUTING PROBLEMS代码框架
gnenerate_data
首先,我们要搞清楚代码的input的数据到底是什么样的,才能知道后面调用各个方法时候,参数是input的这个东西,到底长什么样。
首先我先看了gnenerate_data.py这个文件,一开始以为是这里生成的。因为在这个文件中,以VRP的生成数据内容来看。在generate_vrp_data(dataset_size, vrp_size),意思是多少个实例s,每个s是多少个结点node。这里dataset_size=2,vrp_size=10,生成的数据样式如图:
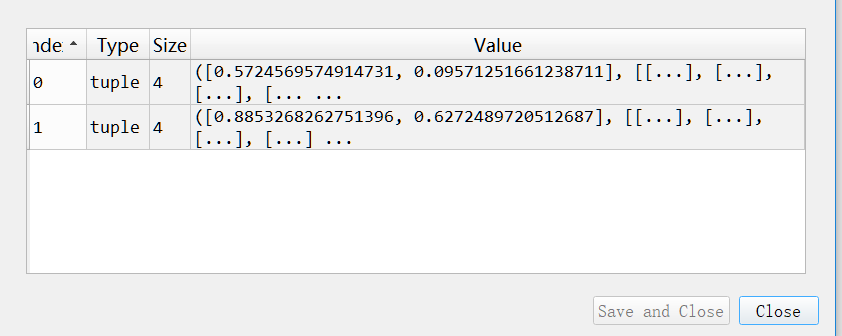
具体其中一个s中的样式:
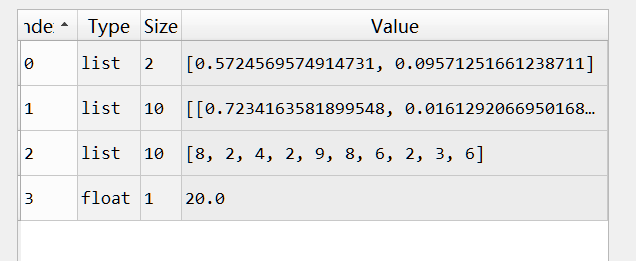
第一个元素是depot坐标,第二个是10个结点坐标,第三个是每个结点的demand,第四个是车的capacity。
但我不知道为什么要写generate_data这个类,因为实际上用来train的数据是在.\problem里生成的。
拿.\problem\vrp来说,在problem_vrp.py中有一个VRPDataset的类,它最后生成的dataset数据样式如图所示:
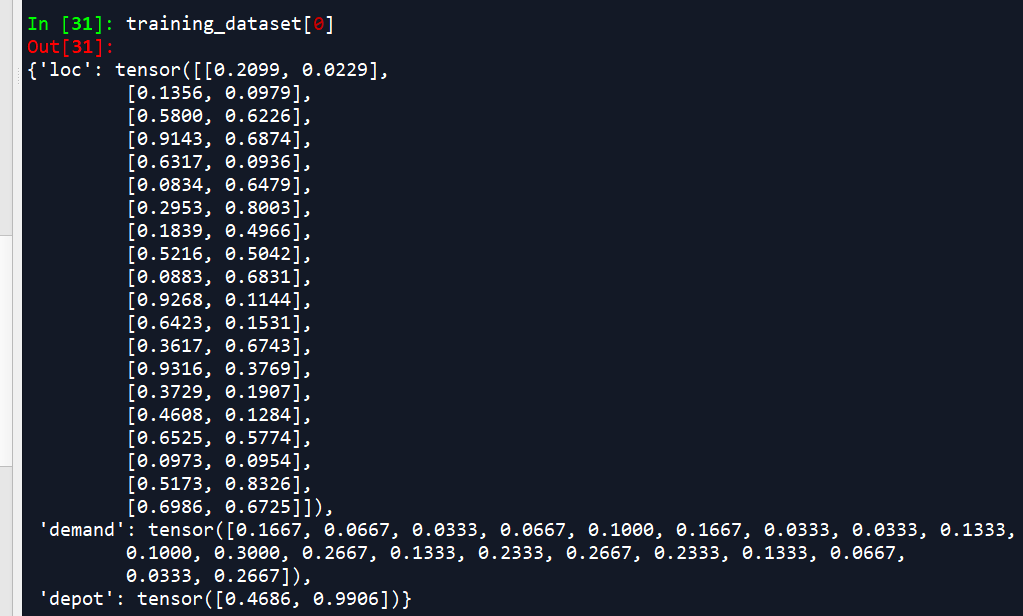
这个就是input了。
GraphAttentionEncoder
总体结构如图
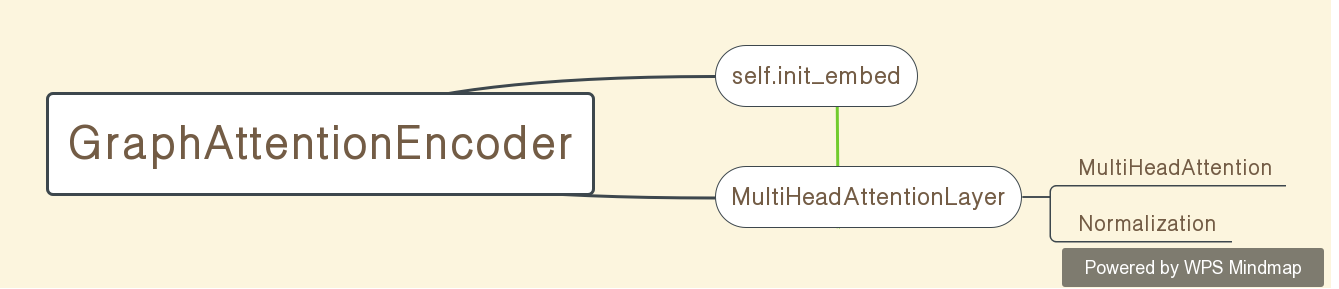
这个class在.\nets\graph_encoder中。GraphAttentionEncoder这个类主要有两个作用,首先讲每个node的特征(在TSP类是2维坐标),通过
self.init_embed = nn.Linear(node_dim, embed_dim) if node_dim is not None else None线性投影到高维空间,然后通过MultiHeadAttentionLayer这个类,得到最后的node embeddings:h和graph embedding:h`(h丶代表横杠)。
#这里的self.layers就是论文中N层MHA连接FF的结构
self.layers = nn.Sequential(*(
MultiHeadAttentionLayer(n_heads, embed_dim, feed_forward_hidden, normalization)
for _ in range(n_layers)
# Batch multiply to get initial embeddings of nodes
#将初始的self.init_embed通过刚刚定义的layers变换到h和h`
h = self.init_embed(x.view(-1, x.size(-1))).view(*x.size()[:2], -1) if self.init_embed is not None else x
h = self.layers(h) 返回的是`h`和`h.meaan`,也就是上面说的,node embeddings和graph embedding。
MultiHeadAttentionLayer
在上面的GraphAttentionEncoder中,用到了MultiHeadAttentionLayer这个类,这个类是将普通的MultiHeadAttention类做了Normalization,再做了论文encoder图片里的FF过程,再Normalization得到的,其中的FF过程在类MultiHeadAttentionLayer中以下部分:
SkipConnection(
nn.Sequential(
nn.Linear(embed_dim, feed_forward_hidden),
nn.ReLU(),
nn.Linear(feed_forward_hidden, embed_dim)
) if feed_forward_hidden > 0 else nn.Linear(embed_dim, embed_dim)
),
Normalization(embed_dim, normalization)
AttentionModel
attention_model.py在.\nets里,在类AttentionModel中,这里是包括了Encoder和Decoder。
self.embedder是上面GraphAttentionEncoder的实例。然后通过embeddings, _ = self.embedder(self._init_embed(input))得到embeddings。
这里self._init_embed(input),是为了将‘depot’、‘loc’和‘demand’在input区分出来做初始化的embed(nn.Linear),然后再进行encoder。
再通过_log_p, pi = self._inner(input, embeddings)进行Deconder。具体在_inner()这个方法里。这里Decoder的过程可以自己去看,不难懂。然后主要是mask这里比较难理解。下面说说mask的过程。
在_innder()Decoder的过程里,首先是state = self.problem.make_state(input),以下的problem拿problem_vrp.py的CVPR()这个类来说,satate = CVPR.make_state(input),将上面说的input作为输入,得到了一个StateCVRP.initialize()(StateCVRP在.\problems\vrp\state_cvrp.py中),是StateCVRP类里的参数初始化的结果,初始化一些参数是拿input中的‘depot’、‘loc’、‘demand’做的。得到的这个state,在_innder()中就可以调用StateCVRP()类里的各个方法,例如state.all_finished()。state.get_finished()。具体代码里:
#根据上一节GraphEncoder得到的embeddings,得到fixed
# Compute keys, values for the glimpse and keys for the logits once as they can be reused in every step
fixed = self._precompute(embeddings)
batch_size = state.ids.size(0)
# Perform decoding steps
i = 0
while not (self.shrink_size is None and state.all_finished()):
if self.shrink_size is not None:
unfinished = torch.nonzero(state.get_finished() == 0)
if len(unfinished) == 0:
break
unfinished = unfinished[:, 0]
# Check if we can shrink by at least shrink_size and if this leaves at least 16
# (otherwise batch norm will not work well and it is inefficient anyway)
if 16 <= len(unfinished) <= state.ids.size(0) - self.shrink_size:
# Filter states
state = state[unfinished]
fixed = fixed[unfinished]
# **根据fixed和state得到mask**
log_p, mask = self._get_log_p(fixed, state) 最关键的,mask虽然在`self._get_log_p()`这里返回的,但在这个方法中,`mask = state.get_mask()`得到了mask,所以还是得去`state_cvrp.py`中去看,也就是:
def get_mask(self):
"""
Gets a (batch_size, n_loc + 1) mask with the feasible actions (0 = depot), depends on already visited and
remaining capacity. 0 = feasible, 1 = infeasible
Forbids to visit depot twice in a row, unless all nodes have been visited
:return:
"""
if self.visited_.dtype == torch.uint8:
visited_loc = self.visited_[:, :, 1:]
else:
visited_loc = mask_long2bool(self.visited_, n=self.demand.size(-1))
# Nodes that cannot be visited are already visited or too much demand to be served now
mask_loc = (
visited_loc |
# For demand steps_dim is inserted by indexing with id, for used_capacity insert node dim for broadcasting
(self.demand[self.ids, :] + self.used_capacity[:, :, None] > self.VEHICLE_CAPACITY)
)
# Cannot visit the depot if just visited and still unserved nodes
mask_depot = (self.prev_a == 0) & ((mask_loc == 0).int().sum(-1) > 0)
return torch.cat((mask_depot[:, :, None], mask_loc), -1) 我理解的是里面应该用了位操作的方式,具体没有细看(因为太难了哭泣。。。),欢迎各位大佬交流。反正就是0是没有mask,1是mask。后面的就不难懂了:
# Select the indices of the next nodes in the sequences, result (batch_size) long
selected = self._select_node(log_p.exp()[:, 0, :], mask[:, 0, :]) # Squeeze out steps dimension
#选好的结点进行更新,以避免下次再选
state = state.update(selected)
# Now make log_p, selected desired output size by 'unshrinking'
if self.shrink_size is not None and state.ids.size(0) < batch_size:
log_p_, selected_ = log_p, selected
log_p = log_p_.new_zeros(batch_size, *log_p_.size()[1:])
selected = selected_.new_zeros(batch_size)
log_p[state.ids[:, 0]] = log_p_
selected[state.ids[:, 0]] = selected_
# Collect output of step
#输出的概率和pi,也就是序列
outputs.append(log_p[:, 0, :])
sequences.append(selected)
i += 1
# Collected lists, return Tensor
return torch.stack(outputs, 1), torch.stack(sequences, 1)
reinforce_baselines
具体我们只看类RolloutBaseline(),因为论文的b(s)就是用的这个做基准。这个类继承了Baseline()的方法,当具体方法还是在自己RolloutBaseline里定义的。在train.py生成traing_datase的时候,用到baseline.wrap_dataset这个函数,在RolloutBaseline.wrap_data(dataset)这个方法里,就是将输入的dataset作为dataset,和rollout后的dataset(也就是evaluation后的dataset)。至此得到了用来train的dataset。也就是在train.py中的:
training_dataset = baseline.wrap_dataset(problem.make_dataset(
size=opts.graph_size, num_samples=opts.epoch_size, distribution=opts.data_distribution))
training_dataloader = DataLoader(training_dataset, batch_size=opts.batch_size, num_workers=1)
train
理解了上面,train.py这个就不难理解,在train_epoch()这个方法里,得到了刚刚上面说的training_dataset后,每个epoch就用train_batch()这个方法去训练,在这个方法里,先把每个dataset每个batch的数据进行baseline.unwrap_batch(batch),是上面wrap_dataset的反过程,得到用来train的data:x和对该data做过evaluation后的baseline:bl_val然后将x放进model里面,例如AttentionModel(),得到cost和log_likelihood,然后评估baseline,后面都很简单了,直接放代码:
# Evaluate baseline, get baseline loss if any (only for critic)
bl_val, bl_loss = baseline.eval(x, cost) if bl_val is None else (bl_val, 0)
# Calculate loss
reinforce_loss = ((cost - bl_val) * log_likelihood).mean()
loss = reinforce_loss + bl_loss
# Perform backward pass and optimization step
optimizer.zero_grad()
loss.backward()
# Clip gradient norms and get (clipped) gradient norms for logging
grad_norms = clip_grad_norms(optimizer.param_groups, opts.max_grad_norm)
optimizer.step()
在train_epoch()里训练后,再做 baseline.epoch_callback(model, epoch),更新(与否)模型参数。更新的条件和方法可以见每个baseline.epoch_callback()中,l例如RolloutBaseline.epoch_callback()
run
在run.py里其实就没什么了,就是从options.py得到的命令行的参数,去进行各种参数赋值和初始化,然后调train.py里的train_epoch()方法去训练而已。
最后
这是我读后的大概框架,我只选了最主要的部分,这个project提供了很多其他选择,但框架不变,只是把里面零件换成另一个选项,处理旁通。例如problem可以选很多,decoder可以有attentionmodel,也可以有pointermodel,baseline有RolloutBaseline也有 CriticBaseline什么的。自己可以根据需要去细细读。总得来说这个project写的很牛批。涉及很多东西,也是很大的一个project了相比而言。
我读的有些头绪其实花了蛮久时间的,有很多地方其实还是不太明白的。如果有错误,欢迎各位大佬指正嗷~