论文连接 这篇文章发表在 ICLR 2019。
ATTENTION, LEARN TO SOLVE ROUTING PROBLEMS!
标题的Attention很取巧啊,一语双关。
Abstract
这篇文章主要是用REINFORCE的方法去训练网络,解决组合优化问题(combinatorial optimization problems),也就是用了RL的deterministic greedy rollout?,比value function(值函数,Q(s,a)和V(s,a)那类的函数)的效果好。网络的话借鉴了Transformer,在Encoder部分用了GraphAttentionEncoder(代码里面的类名),Decoder用了AttentionModel(代码里的类名)。这套方法用来解决旅行商问题(Travelling Salesman Problem),简称TSP,在100个结点内都能达到接近最优结果。应用在车辆路径问题(Vehicle Routing Problem)简称VRP的两个变种Orienteering Problem(OP)和PRize Collecting TSP(PCTSP)也都有很不错的表现。
Introduction & Related work
这部分就不详细介绍了,这里有个比较皮的地方是TSP他实例成Travelling Scientist Problem,哈哈哈哈旅行的科研狗。
这篇文章引的几篇比较重要的文章,方便理解。(不限于在Introduction and Related work这两部分引用的):
- Neural Combinatorial Optimization with Reinforcement Learning 比较早(不知道是不是最先)用强化学习的思想去解决TSP问题。
- Pointer Networks 提出指针网络,是对attention机制的做后输出做了修改。具体可以自行去了解~而我们这篇文章在encoder和decoder部分所使用的框架是Transformer architecture。在下面的encoder部分会详细介绍该结构。而且上面这篇Neural Combinatorial Optimization with Reinforcement Learning也是基于指针网络的,不过他们用的强化学习的 Actor-Critic的方法去训练网络的。
- Graph Attention Networks 将整个图形作为输入,而不是序列作为输入。类似下面Attention Model的这张图。
- Attention Is All You Need 提出的Transformer结构,然后本文修改了其结构,作为encoder和decoder。
Attention Model
首先从构建输入来说:对一每一个问题实例s来说,s内包括n个结点(nodes,第i个结点的特征xi,对于TSP,是坐标,然后xi之间是全连通的。这一个实例s就可以当做一个图形(Graph)作为输入。也就是如下面这样,直接把这幅图当做输入,只不过这10个结点的信息是以坐标为特征的。
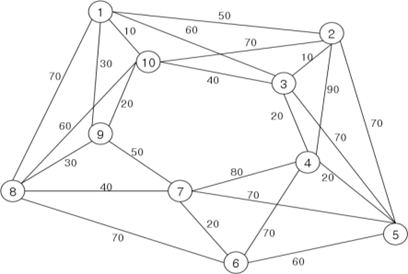
将图形作为输入比将节点作为序列输入更好,因为它消除了对输入中给出城市的顺序的依赖性,只要它们的图形坐标位置不变。也就是说,无论我们如何对节点进行排列,只要给定的图不变,那么输出就不会变,这是与序列方法相比的优势所在。
编码器(encoder)产生出所有输入节点的嵌入(embeddings),解码器(decoder)根据输入的节点产生输出输出序列,一次一个点。解码器的输入由3个部分组成:1. 编码器的嵌入(encoder embeddings) 2.根据问题而定的遮盖(mask 不知道怎么翻译好,反正就是遮住那些因为条件设置不能去的点) 3.上下文向量(context)。下面详细说明。
Encoder
该部分最重要的是使用了修改版的Transformer的结构(也就是不用positional encoding 部分),下面先介绍在Attention is All You Need中原版的Transformer结构。
Transformer Architercture
如下图所示:
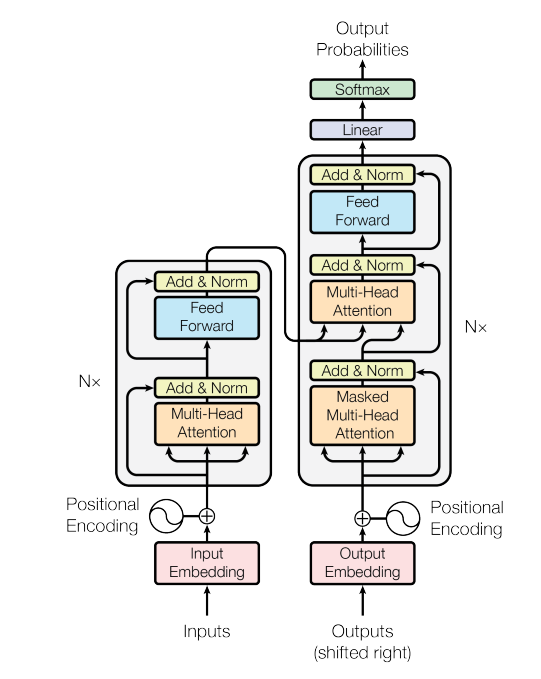
左边是encoder部分,右边是decoder部分。Nx中N=6,有6层相同结构。每一层包的Encoder含两个sub_layer。一个是Multi-Head Attention layer,然后是一个全连接层(Feed Forward)。Decoder也是6层,每一层有三个sub_layer。前两层都是Multi-Head Attention,最后是全连接层。而第一个MHA是self-attention layer的堆叠,第二个MHA是encoder-decoder attention layer的堆叠。
多头注意力机制(Multi-Head Attention)根本上是的堆叠self-attention。
Encoder的部分,如果把MHA换成单层的话,就是self—Attention,如下图所示。
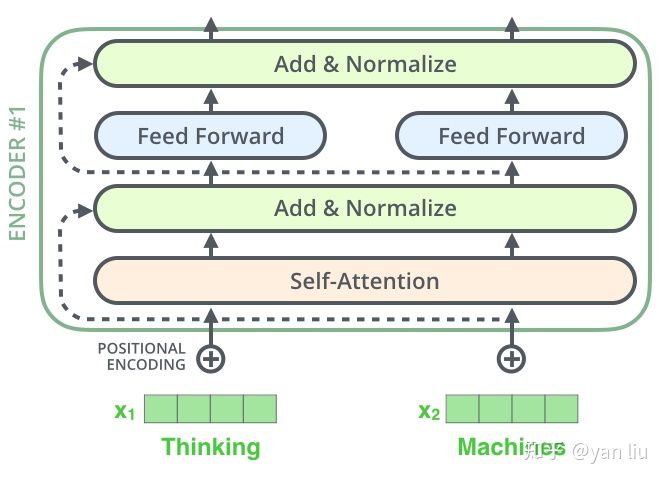
输入的单词x通过Word2Vec等词嵌入方法转化成嵌入向量(Embedding)后成为X,经过self_attention变成Z向量:
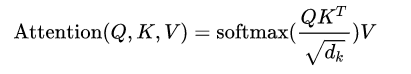
进入Feed Forward。这个全连接有两层,第一次是Relu,第二层是一个线性激活函数,表示为:
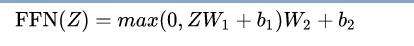
具体Z向量计算形象入下图:
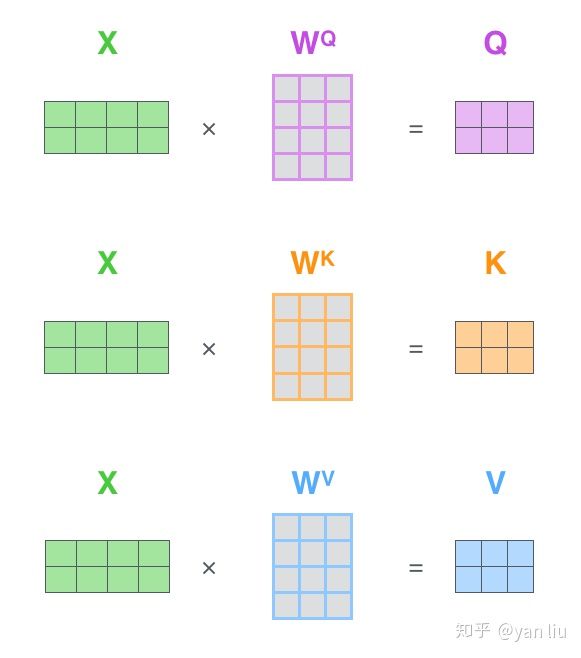
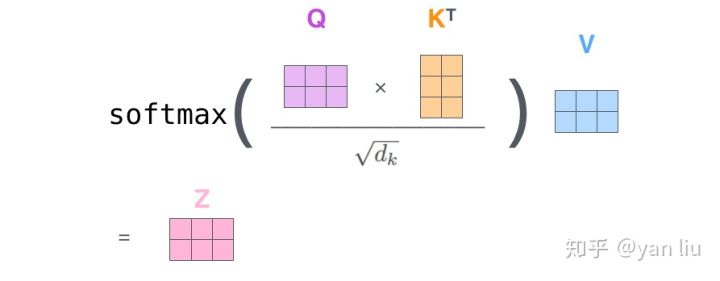
X分别成QKV三个权重矩阵,得到QKV三个向量,再经过Softmax得到Z向量,Z再经过全连接层输出给Decoder的encoder-decoder attention layer。
理解了单层,就可以理解MHA:
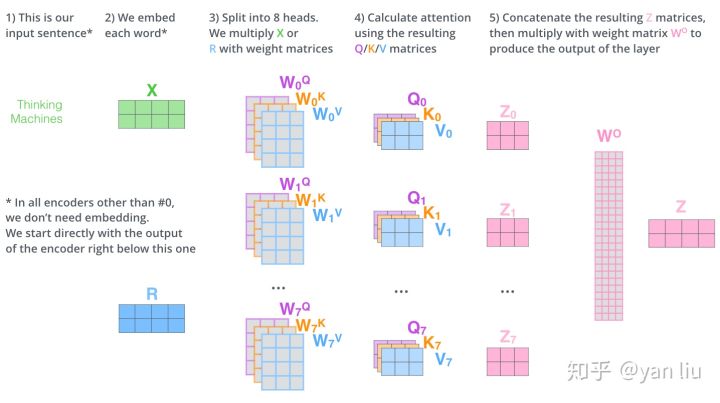
想当于将h个不同的self-attention集成(ensemble),如图h=8,得到8个Z向量(相当于CNN中多个特征向量)进行拼接,得到一个大的特征矩阵,经过一层全连接输出后得到MHA的Z。如果形象点理解的话,就是将Self-Attention这一个过程随机初始化8次,相当于映射到不同的子空间,然后拼接起来并乘以权重向量产生输出层。相当于我们从多种角度来理解同一个句子,以求更加完备的语义表达。
Transformer Architercture:Decoder
理解了上面的话,在第二层的MHA实现的是encoder-decoder attention的堆叠,Q来自Decoder的第一层MHA输出,K和V均来自Encoder的输出。
Transformer Architercture:Positional Encoding
由于这篇文章对Positional encoding做了修改,这块直接不用。所以这里不做介绍。
所以介绍完Transformer这一节,回到本文的Encoder中,对于encoder第一层隐藏层h(0)来说,首先将输入的特征xi(对于TSP是2维的特征向量),通过线性投影变成128维:
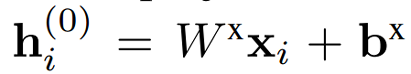
然后Encoder的结构如下:
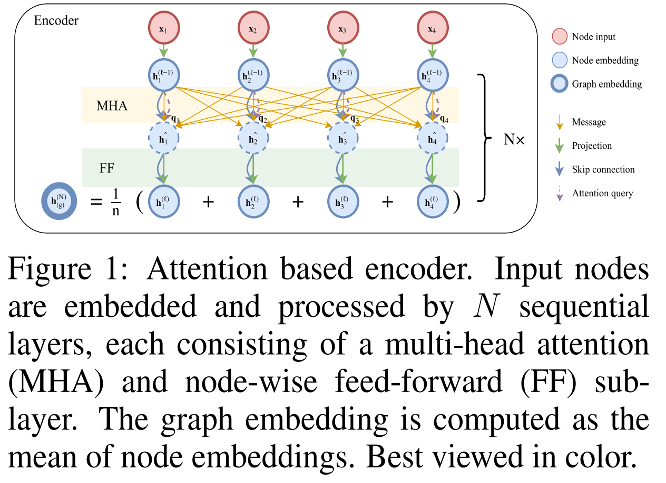
最后将最后结点的embeddings的平均作为图形的嵌入(graph embedding),并且将结点的embdedding和graph embedding作为decoder的输入。本文的MHA用了8层(M=8),然后最后全连接层用了一层512的隐藏层,Relu激活。
Decoder
Decoder的结构图如下:这里和Transformer的Decoder结构不太一样了。
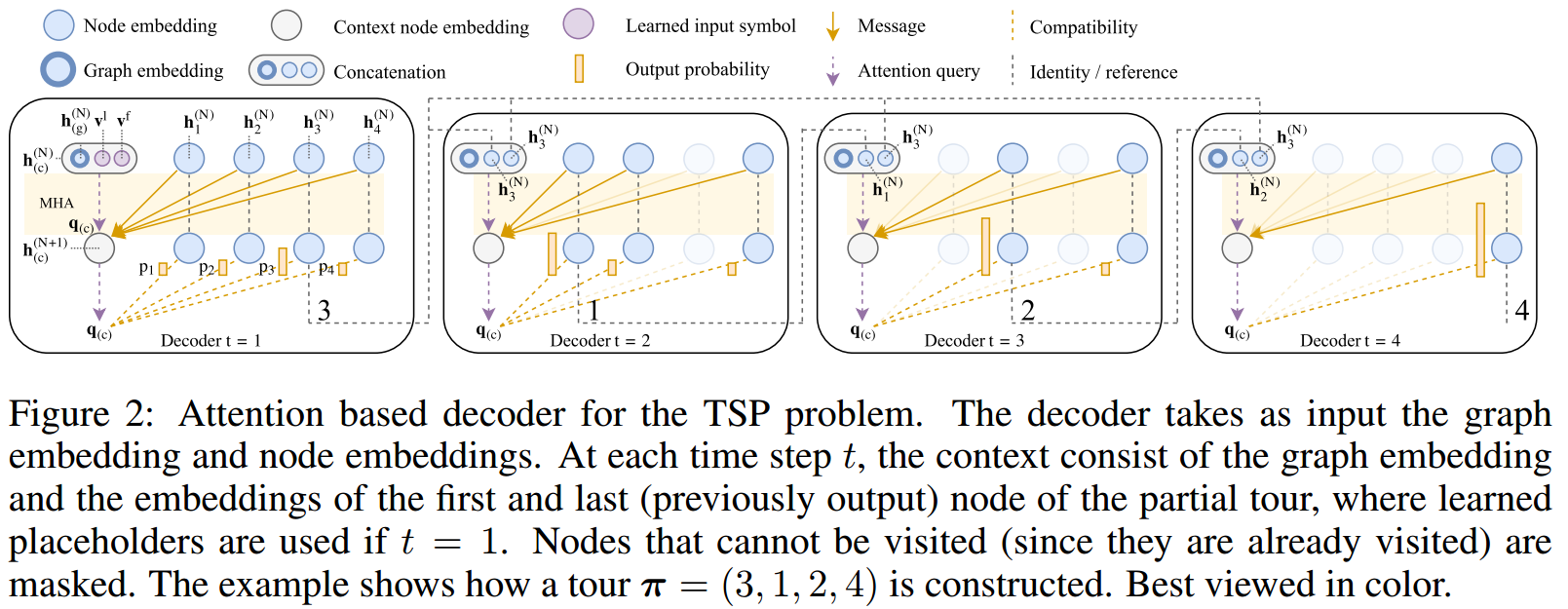 Encoder的graph embedding和结点的embedding当做是Decoder的输入。并且将Graph embedding和input symbol(上一层的输入的隐藏层h和第一次输出的隐藏层h)拼接到一起(左上并列3个圈)。也就是如下公式:
Encoder的graph embedding和结点的embedding当做是Decoder的输入。并且将Graph embedding和input symbol(上一层的输入的隐藏层h和第一次输出的隐藏层h)拼接到一起(左上并列3个圈)。也就是如下公式:
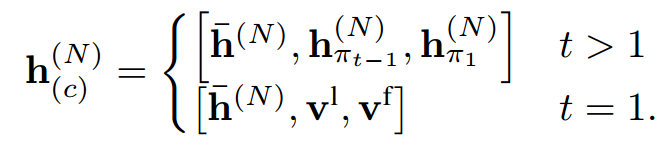
然后根据MHA计算出新的context node embedding。然后每一个MHA的self_attention(也就是每一个head)的q(c)的计算如下:
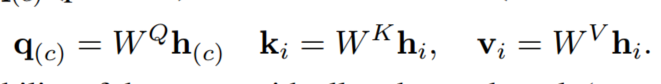
REINFORCE with greedy rollout baseline
其实这里的思想如果了解RL的话比较简单,首先选一个b(s)作为baseline,本文是用 greedy rollout baseline,这个baseline类似于DQN的target_net,是周期性更新参数的。
所以损失函数就是现在网络生成的策略的总路程长(在TSP问题里是总路程)L(π),和这个b(s)的里程差值,可以理解为当前策略和基线策略的差距。如下:
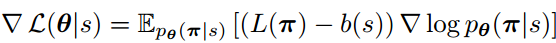
每个epoch结束,通过在10000个实例s的t-test,如果当前策略有显著性提高,就用当前策略替换baseline的参数。算法如下:

结语
这篇文章还是挺难读的,由于我做RL之前一直没用到NLP有关网络的知识,所以Attention这些都是第一次接触,费了很多功夫,这篇文章可能也有很多纰漏,所以大家可以只做参考~还是要自己去读下论文。而且,文章代码更难读!!!下一篇如果我代码看明白的话,会写下该文的代码结构。。。